Building AI That Actually Helps Kids Learn
Modern artificial intelligence offers the possibility of providing personalized tutoring at scale. The core question is whether AI systems can deliver individualized attention comparable to dedicated human tutors while remaining practically deployable in real educational environments.
Transformer architectures, reinforcement learning, and knowledge tracing form the foundation of educational AI systems. These technologies focus on modeling how students learn and adapt to their individual needs through sophisticated mathematical frameworks.
Transformer-based models like SAKT, SAINT, and TCFKT can track student knowledge with remarkable precision. Systems like TutorLLM combine BERT-based student modeling with large language models to create personalized recommendations. These powerful models need to run fast enough for real classrooms, requiring compression techniques like distillation, quantization, and pruning.
The Promise of Personalized Tutoring at Scale
Benjamin Bloom's research established that personalized tutoring produces learning gains roughly two standard deviations above typical classroom instruction, known as the "2 sigma problem." The challenge is achieving this level of individualized instruction at scale.
AI systems have the potential to capture elements of intuitive understanding found in expert tutors. These systems could track learning patterns, predict difficulties, and adapt in real-time to individual student needs.
Educational AI systems aim to amplify teachers' ability to see and respond to each student's needs. The core challenge involves building systems sophisticated enough to understand learning while remaining fast enough to run on standard classroom technology.
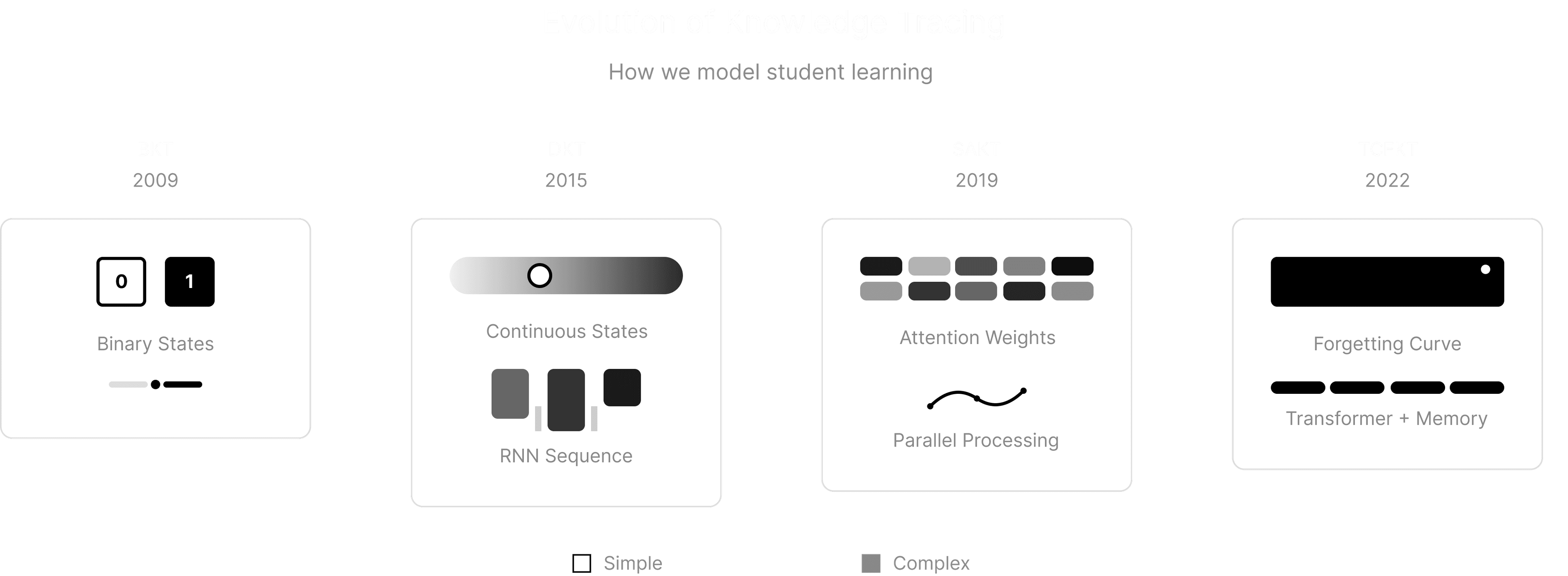
Knowledge Tracing: Modeling What Students Know
Knowledge tracing maintains a running estimate of what a student knows based on their learning interactions. This computational approach models how knowledge moves in and out of a student's mind through mathematical frameworks grounded in cognitive science research.
Bayesian Knowledge Tracing models students as either knowing or not knowing a skill, with probabilistic transitions between states. Deep Knowledge Tracing uses RNNs to capture the continuous nature of human learning. Transformer-based models represent the current state-of-the-art approach.
Consider the SAKT (Self-Attentive Knowledge Tracing) model. It uses self-attention to ask a profound question: when predicting how a student will perform on their next problem, which of their past exercises matter most? A student struggling with quadratic equations might benefit more from reviewing their algebra fundamentals than their most recent attempts. The attention mechanism learns these relationships automatically, creating connections across a student's entire learning history.
TCFKT (Temporal Convolutional networks and Forgetting Knowledge Tracing) addresses the reality that students forget by including a "forgetting factor" that acknowledges skills decay over time, combined with convolutional layers that capture local patterns in learning sequences. Research by Xu and colleagues on tutoring data from ASSISTments and other platforms demonstrates 3-4% improvements in prediction accuracy over baseline models.
The mathematical elegance of knowledge tracing lies in this formulation:
where represents whether a student will get the next question right, encodes everything we know about that question, captures their current knowledge state, and is our transformer model trying to understand the learning process.
[INTERACTIVE VISUALIZATION: Attention Patterns in Student Learning - A heatmap showing which past problems a transformer model focuses on when predicting a student's next response. For a struggling algebra student, we might see the model paying attention to their basic arithmetic patterns from weeks ago, not just yesterday's quadratic equations. This demonstrates how attention mechanisms find hidden connections in learning trajectories.]
Reinforcement Learning for Optimal Content Sequencing
Once we can model what a student knows, the next challenge is deciding what they should learn next. Reinforcement learning approaches this by training an AI agent to sequence educational content optimally based on learning theory and observed outcomes.
The RL agent observes a student's knowledge state and chooses what content to present next. Through trial and optimization, the system can discover patterns such as which students learn best when geometric concepts are introduced before algebraic ones, or when they receive targeted review of fundamentals before tackling new material.
Research by Bassen and colleagues on "Reinforcement Scheduling" demonstrates training an agent using PPO (proximal policy optimization) to sequence content for online learners. Their published results show students under the RL policy performed better on assessments while completing fewer assignments, suggesting the AI optimized teaching effectiveness by focusing on exactly what each student needed.
In their controlled evaluation with over 1,000 learners, students using the RL scheduler showed significantly higher learning gains and lower dropout rates compared to those following fixed curricula. These findings demonstrate the potential for adaptive curriculum sequencing to improve educational outcomes.
[ANIMATED DEMO: RL Agent Learning to Teach - An interactive simulation showing how an RL agent learns optimal teaching strategies over time. Early iterations make suboptimal decisions (like assigning advanced calculus to students who haven't mastered algebra). Through reinforcement learning, it discovers nuanced patterns: certain student profiles need more visual examples, others learn better with immediate feedback. The reward curves demonstrate how the agent improves at maximizing learning while minimizing frustration.]
Large Language Models as Educational Tutors
Large language models like GPT-4 can explain complex concepts effectively but have a tendency toward hallucinations when accuracy is critical. For educational content, Retrieval-Augmented Generation (RAG) becomes essential for grounding responses in verified information.
The RAG approach is elegant: before generating an explanation, the system first searches through verified educational content—textbooks, lesson plans, worked examples—to find relevant information. Then it uses this grounded knowledge to generate responses that are both accurate and personalized to the student's current understanding.
TutorLLM represents one implementation of this approach, combining a BERT-based knowledge tracing model with a RAG-enhanced GPT to generate explanations. The system includes a content management component that continuously gathers course materials and contextualizes them with individual student learning progress.
Published evaluations of TutorLLM show improvements in both student satisfaction scores and assessment performance compared to generic LLM tutors. These improvements stem from understanding each student as an individual learner rather than providing one-size-fits-all explanations.
Mathematically, we can represent the RAG pipeline as:
where we retrieve relevant content from our educational knowledge base , combine it with the student's current state and their question , then feed everything to the language model. This approach gives the AI both comprehensive domain knowledge and perfect understanding of where the student is in their learning journey.
[STEP-BY-STEP RAG DEMO: From Question to Personalized Answer - Visualization showing how a student question like "I don't understand why fractions work this way" flows through: 1) Knowledge retrieval (finding relevant textbook sections, worked examples), 2) Student state integration (this student struggles with division, learns best with visual examples), 3) LLM generation (creating a response that's both accurate and perfectly tailored to this learner). The demonstration shows how these components work together.]
Multi-Modal Learning Analytics
Students reveal information about their understanding through multiple channels beyond just their answers. Time spent on problems, patterns in question-answering behavior, and help-seeking behaviors provide important signals for understanding learning progress.
Modern educational AI systems are becoming increasingly sophisticated at incorporating these multi-modal signals. Research datasets like ES-KT-24 include not just question-answer pairs but also behavioral logs and interaction patterns. Systems like MLFBK (used in TutorLLM) embed different types of features—student characteristics, skill requirements, question properties, and response patterns—into unified representations.
The technical challenge is fascinating: how do you fuse text embeddings (from question content), temporal signals (time spent), categorical features (student grade level), and behavioral patterns (clicking, scrolling, help-seeking) into a coherent model? Early fusion concatenates everything before processing, late fusion combines outputs from separate models, and attention-based fusion lets the model learn which signals matter most for each prediction.
However, every additional modality increases computational cost. In research environments, you can allocate abundant computational resources. In real classrooms with limited hardware and connectivity, every millisecond matters. This fundamental tension between comprehensive modeling and practical deployment represents one of the core challenges in educational AI.
[REAL-TIME STUDENT DASHBOARD: The Data Behind Learning - Visualization of all the signals an AI tutor processes: text responses, time-on-task metrics, click patterns indicating hesitation, attention patterns from interaction logs. Shows how early fusion, late fusion, and attention-based fusion would combine these streams differently. The goal: demonstrate that modern educational AI can perceive learning as comprehensively as experienced human teachers.]
Model Optimization for Real-Time Classroom Performance
Transformer models requiring several seconds to respond severely impair the learning experience. Students need immediate feedback when encountering difficulties. Real-time performance is essential for maintaining engagement and educational effectiveness.
Knowledge distillation involves training a smaller "student" model to mimic a larger "teacher" model. DistilBERT has 40% fewer parameters than BERT while retaining 97% of its accuracy and running 70% faster. This approach enables deployment of sophisticated knowledge tracing on resource-constrained devices.
Quantization converts model weights from 32-bit to 8-bit precision (or even 4-bit with techniques like GPTQ) to dramatically reduce memory usage and computational requirements. Educational applications can run sophisticated models on mobile devices through quantization combined with efficient batching strategies.
Pruning removes network components that contribute least to educational predictions. For knowledge tracing models, this is particularly elegant because often only certain skills are relevant for each question, enabling sparse attention patterns that align with the actual structure of learning.
Linear attention mechanisms reduce complexity from to in sequence length, which matters when tracking long learning histories. Hybrid architectures can combine lightweight transformers for real-time interactions with larger models running asynchronously for deeper analysis.
[INTERACTIVE PERFORMANCE COMPARISON: The Speed vs. Intelligence Trade-off - A slider interface demonstrating how different optimization techniques affect both response time and educational effectiveness. Adjusting compression parameters shows model size reduction, latency improvements, and changes in personalization quality. This helps visualize the careful balance required to make AI fast enough for classrooms while maintaining educational value.]
Research Results and Technical Achievements
Published research demonstrates significant progress in educational AI. Xu and colleagues' evaluation of TCFKT against other knowledge tracing approaches on datasets like ASSISTments 2017 and Statics2011 consistently achieved the highest AUC scores, with 3.5-4% improvements representing thousands of more accurate predictions about student understanding.
The reinforcement learning research shows compelling results. Bassen's controlled trial with 1,000 learners found that students under RL scheduling achieved significantly higher test scores while completing fewer assignments (p<0.05 on both measures), with lower dropout rates compared to self-paced controls.
TutorLLM evaluations demonstrated a 10% increase in satisfaction scores and 5% improvement in quiz performance over baseline LLM tutors. These gains came specifically from personalization and grounding—the system understanding each student as an individual rather than providing generic explanations.
On the efficiency front, progress has been substantial. Real-time tutoring applications typically target sub-100ms response times, which is achievable with optimized models on modern mobile hardware. Many successful deployments use hybrid cloud-edge architectures: lightweight models handle immediate interactions while comprehensive analysis happens asynchronously in the background.
[RESEARCH IMPACT VISUALIZATION: Beyond the Numbers - A compelling visualization showing not just AUC improvements and statistical significance, but their implications for real students: reduced dropout rates, improved confidence in STEM subjects, more efficient learning pathways. Animated counters might show "Students who persisted with challenging material: +2,847" or "Learning efficiency gains: 15% improvement." The human impact behind the research statistics.]
Current Technical Challenges
The Cold Start Problem: Most schools lack extensive learning data histories. Building personalized models for new students requires transfer learning approaches: pre-training on large educational datasets then fine-tuning on school-specific data. Synthetic student simulation shows promise for bootstrapping models when real data is sparse.
The Accuracy vs. Speed Dilemma: Every millisecond of latency matters in classroom environments, while every parameter reduction potentially affects educational effectiveness. Optimal deployment often involves hybrid approaches: lightweight models for immediate feedback combined with periodic consultation of more comprehensive models for deeper analysis.
Privacy-Preserving AI for Education: Student data requires exceptional protection under FERPA and COPPA regulations. Edge inference using mobile AI accelerators (like Apple's Neural Engine or Google's Edge TPUs) offers a promising path: sophisticated modeling with sensitive data never leaving the device.
Real-World Integration Challenges: Building effective AI models is only part of the solution. Deploying them reliably in actual schools, with existing technology constraints and teacher workflows, requires substantial systems engineering and user experience design.
[DEPLOYMENT REALITY: From Research to Classroom - A split-screen comparison showing "Research Environment" (high-end GPUs, clean data, controlled conditions) vs. "Real Classroom" (older devices, variable connectivity, diverse student needs). Demonstrates how successful systems bridge this gap with edge computing, smart caching, and graceful degradation. The engineering challenges that determine whether research actually benefits students.]
Future Research Directions
Advanced Multi-Modal Understanding: Current systems primarily work with text and basic behavioral signals. Future research might incorporate eye-tracking, speech patterns, and physiological signals to detect cognitive load, though practical classroom deployment remains challenging.
Federated Learning for Education: Schools could potentially benefit from shared AI models without exposing individual student data. Federated learning enables local model training with only aggregate updates shared globally. The privacy benefits are compelling, but technical challenges around data heterogeneity and communication efficiency remain substantial.
Causal Understanding vs. Pattern Recognition: Most current systems are predictive rather than explanatory. They identify students likely to struggle but provide limited insight into underlying causes or optimal interventions. Causal reasoning approaches could identify which instructional strategies actually drive learning improvements.
Metacognitive Skill Development: Current AI tutors focus on domain knowledge—math, science, history—while rarely addressing metacognitive skills like self-regulation, study strategies, and reflection. Future systems might explicitly model and teach these "learning how to learn" skills.
[VISION OF FUTURE EDUCATIONAL AI: Beyond Current Limitations - An interactive prototype demonstrating what truly personalized education might look like: an AI that distinguishes between frustration and confusion, that can explain calculus through music if that matches a student's thinking style, that helps students discover their own learning patterns. Shows the feedback loops between curiosity, understanding, and confidence that create lifelong learners.]
Conclusion
Educational AI research demonstrates significant potential for delivering personalized instruction at scale. Technical achievements include transformer-based knowledge tracing with measurable accuracy improvements, reinforcement learning schedulers that optimize engagement and efficiency, and retrieval-augmented tutors that combine verified educational content with AI personalization.
Model compression techniques make it feasible to run sophisticated educational AI on standard classroom devices. However, the ultimate measures of success are improved learning outcomes: students who persist with challenging subjects, increased confidence in STEM fields, and more effective learning pathways.
The intersection of educational research, machine learning, and systems engineering creates opportunities for scalable personalized education. Success requires technical innovation combined with deep understanding of learning processes and practical classroom constraints.
AI systems that help students find effective learning paths, support teachers in understanding individual needs, and make personalized education more accessible represent one of the most promising applications of artificial intelligence technology.